Structured Generation Visualized

Text is the universal format for data. The code for this post is written in text, communicates with JSON and renders the result with HTML. Every part of that process can be represented with text.
LLMs are trained on a giant corpus of text, but can they generate data? Most of that text is just prose, but many LLMs are also trained on structured formats like code. Let's try asking a LLM to generate structured JSON for a character in this format:
{ "name": string, "description": string, "metadata": { "age": number, "height_cm": number, "weight_kg": number, "hair_color": string, "eye_color": string, } }
Let's use a small model that is good at structured formats and reasoning called Phi-3-Mini. We can use Kalosm to generate and stream the text locally:
// Create a new model. We are using the Phi-3 model which is small and focused on reasoning tasks. let model = Llama::phi_3() .await .unwrap(); // Create a task that generates text for a character let task = Task::builder("You generate data in a JSON format").build(); // Run the task let mut result = task.run(r#"Generate a character with this format: { "name": string, "description": string, "metadata": { "age": number, "height_cm": number, "weight_kg": number, "hair_color": string, "eye_color": string } }"#, &model); // Stream the text into stdout result.to_std_out().await.unwrap();
Running the program sometimes generates valid JSON with reasonable data:
{ "name": "Michael Thompson", "description": "A dedicated software developer with a passion for coding and innovation. Known amongst friends to be an avid reader, particularly of science fiction novels.", "metadata": { "age": 29, "height_cm": 180, "weight_kg": 75, "hair_color": "dark brown", "eye_color": "blue" } }
But other times, it generates nonsense:
{ "name":"Emily Thompson", "description":"A talented graphic designer with an eye-catching style. Emily is known to be creative, friendly and dedicated at her job.", "metadata": { "age":28, "height":165,"cm" :94, "weight":"60","kg", "hair_color":"blonde", "eye_color":"blue" } }
","kg",? That doesn't look right... Ok, so just asking nicely isn't enough. The LLM knows something about the structure of JSON, but it isn't consistent enough to generate valid JSON every time.
We need some way of controlling what the LLM generates to guide it towards our format.
Token Generation
Before we start controlling the output of a language model, lets look at how exactly text generation works. LLM sees text in chunks called tokens. On average, each token is about 2/3 of a word, but depending on the word, it could be the entire word or a single character.
Let's take a look at what tokens look like from the perspective of the LLM. You can see what previous tokens the LLM has seen at the bottom of the visualization and a few of the next possible tokens on the right:
To generate text, LLMs assign a probability to each token and pick a token with a high probability. Picking a token from the list of probabilities is called sampling.
We need to control that sampling process to change influence the token our LLM picks after it assigns a probability to each token. Instead of choosing the most likely token, we can look for only tokens that fit our format.
Defining the Format
To find tokens that fit our format, we need a parser that:
- Incrementally parses new text in a way we can roll back. If the current tokens are
{"age":we need to be able to try addingaand if it fails, roll back to{"age". If our current text is long, our parser shouldn't need to re-parse the entire history for every one of the~128,000possible new tokens - Fails immediately if a new token is invalid. We need to validate every token individually so we don't waste time generating a sequence of tokens and then walking back once we realize it's invalid
Regular Expressions are very well suited for this task. We can compute regular expressions with a finite state machine. Simple regular expressions can be represented with a lookup table which makes storing states and adding characters very cheap.
Here is a regular expression that matches our JSON schema:
\{ "name": "[A-Z][a-z]{1,10} [A-Z][a-z]{1,10}", "description": "[ A-Za-z]+", "metadata": \{ "age": \d{1,2}, "height_cm": \d{1,3}, "weight_kg": \d{1,3}, "hair_color": "[A-Z][a-z]+", "eye_color": "[A-Z][a-z]+" \} \}
Constrained Augmented Sampling
Let's combine our format with the sampler. We can only sample tokens that fit our regex. Even if you choose completely random options from the list of probabilities, the LLM will still generate text that conforms to the format. From the perspective of the LLM, it looks something like this:
Lets see what our LLM generates with our new constraints:
// Create a new model. We are using the Phi-3 model, a small and focused on reasoning tasks. let model = Llama::phi_3() .await .unwrap(); // Create a constraint that checks if the generated text is valid JSON let constraint = RegexParser::new(r#"\{ "name": "[A-Z][a-z]{1,10} [A-Z][a-z]{1,10}", "description": "[ A-Za-z]+", "metadata": \{ "age": \d{1,2}, "height_cm": \d{1,3}, "weight_kg": \d{1,3}, "hair_color": "[A-Z][a-z]+", "eye_color": "[A-Z][a-z]+" \} \}"#).unwrap(); // Create a task that generates text for a character let task = Task::builder("You generate data in a JSON format") .with_constraints(constraint) .build(); // Run the task let mut result = task.run(r#"Generate a character with this format: { "name": string, "description": string, "metadata": { "age": number, "height_cm": number, "weight_kg": number, "hair_color": string, "eye_color": string } }"#, &model); // Stream the text into stdout result.to_std_out().await.unwrap();
The results are much more consistent. The LLM always generates valid JSON because of the constraints. It also generates JSON in a more precise format because we specified everything about the format we wanted. It knows we need exactly two words that start with a capital letter for the name.
{ "name": "Evelyn Archer", "description": "A cunning and resourceful detective with a sharp eye for detail who has solved numerous complex cases in the bustling city of New York during her prime years as an investigator at midlife crisis stage when she starts to question life choices leading up until now that age is just another number", "metadata": { "age": 45, "height_cm": 168, "weight_kg": 70, "hair_color": "Auburn", "eye_color": "Hazel" } }
Accelerated Structured Generation
You may have noticed that in some positions, the LLM only has one valid token choice. We don't actually need to run the LLM in these cases. Instead, we can choose the next token directly. In practice, this acts a bit like autocomplete. Once the LLM starts generating a specific part of the grammar, the rest of the chunk gets filled in automatically:
Instead of choosing each of the ~ 16 tokens, we only need to choose between the ~ 4 interesting tokens! The LLM will still need to read the new text, but that process is much faster than generating new tokens.
Beyond REGEX
REGEX is great for simple constraints, but it is both tedious to write and limited to simple patterns. There are also some structures you just can't express with REGEX. For example, you can't use REGEX to validate any recursive structures, including the general version of JSON itself!
Let's take a look at two alternative approaches to validating text: Deriving parsers automatically and writing custom validators.
Deriving Parsers
If you don't need complete control over the syntax the model uses to generate JSON, you can just derive a parser for JSON from a type:
// Cargo.toml // [dependencies] // kalosm = { version = "0.3", features = ["language", "metal"] } // tokio = { version = "1.37.0", features = ["full"] } use kalosm::language::*; // Define a type for the character #[derive(Parse)] struct Character { name: String, description: String, metadata: Metadata, } // Define a type for the metadata #[derive(Parse)] struct Metadata { // You can easily set ranges for numbers. In regex this would need to be `100|\d\d|[1-9]` #[parse(with = U8Parser::new(1..=100))] age: u8, height_cm: u8, weight_kg: u8, hair_color: String, eye_color: String, } #[tokio::main] async fn main() { // Create a new model. We are using the Phi-3 model which is small and focused on reasoning tasks. let model = Llama::phi_3() .await .unwrap(); // Create a constraint that parses our character type let constraint = Character::new_parser(); // Create a task that generates text for a character let task = Task::builder("You generate data in a JSON format") .with_constraints(constraint) .build(); // Run the task let mut result = task.run(r#"Generate a character with this format: { "name": string, "description": string, "metadata": { "age": number, "height_cm": number, "weight_kg": number, "hair_color": string, "eye_color": string } }"#, &model); // Stream the text into stdout result.to_std_out().await.unwrap(); // BONUS: Parsing is validation. If you derive a parser, you automatically get out parsed data! let parsed: Parsed = result.parse().await.unwrap(); }
The output is very similar to the regex version of the parser, but it is much simpler to create. It is also easier to define more strict constraints like limiting the age to a specific range:
Creating Custom Parsers
If you need even more control, you can write a custom parser for your format. Unlike regex, your parser can parse languages that require context like html.
Regular languages are limited to patterns parsable with a set number of states. Recursive structures like HTML require an unbounded stack to keep track of the current depth of the HTML. In Kalosm, you can implement a custom parser to parse any language with an arbitrary number of states.
use kalosm::language::*; #[tokio::main] async fn main() { let model = Llama::phi_3().await.unwrap(); let task = Task::builder("The assistant generates plain HTML") .with_constraints( html_parser::Element::new_parser() ) .build(); let input = prompt_input("> ").unwrap(); let mut output = task.run(input, &model); output.to_std_out().await.unwrap(); let html: html_parser::Element = output.await.unwrap(); println!(); println!("{:#?}", html); }
Because parsing runs in native rust code, you can parse even complex languages like HTML with constraints for elements, attributes, and values in real-time:
The format the LLM generates can influence generation quality significantly. Depending on what structures the model is trained on, it may perform much better generating HTML than describing HTML with a JSON object.
Sampler Aware Structured Generation
We are currently running the parser for every one of the 128,000 tokens every time we add a new token to the sequence. That wasn't an issue for REGEX where each new token is only a lookup away, but it can be slow for more complex parsers.
Instead of running the parser for every token, we can use the structure of the sampler to skip parsing some tokens.
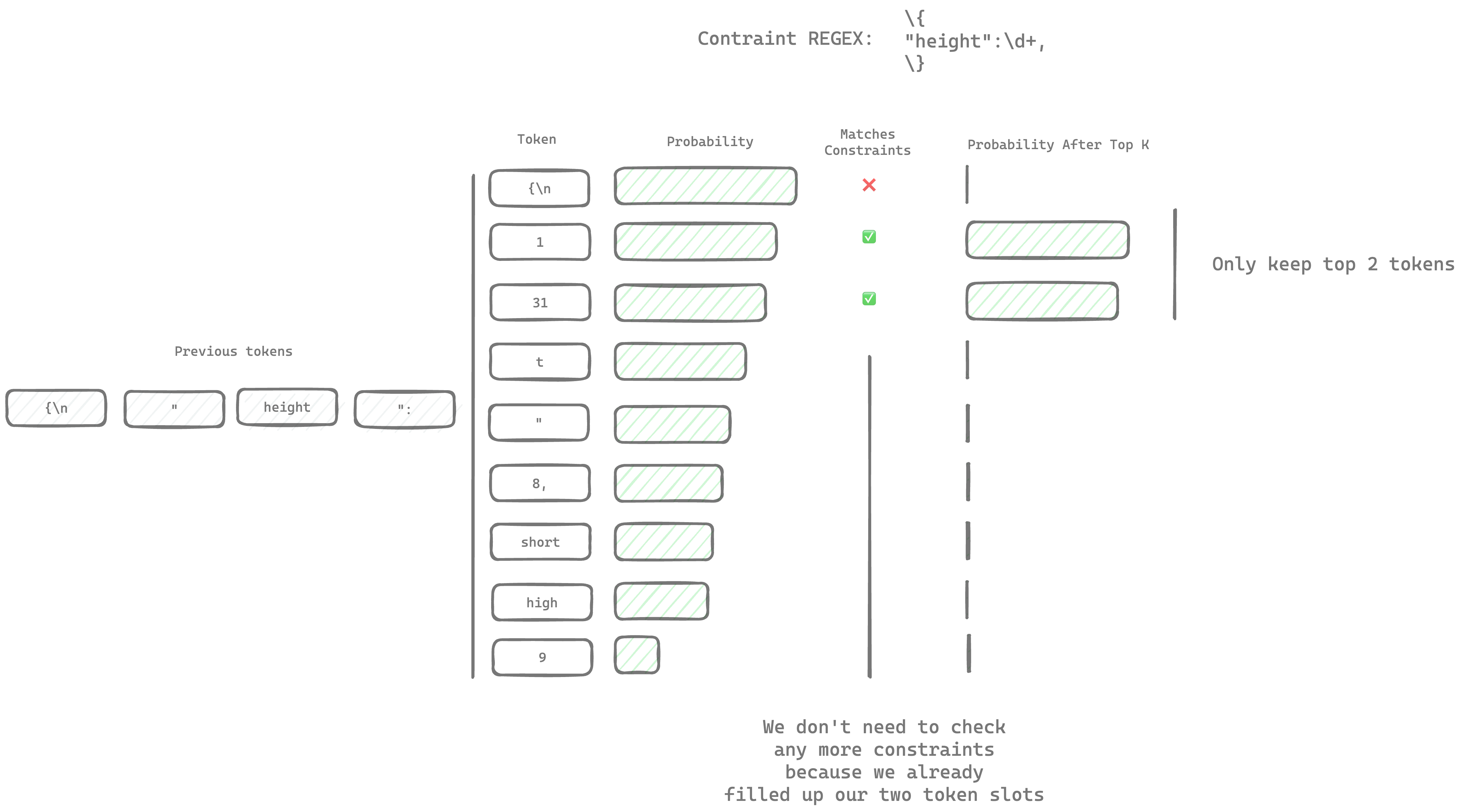
There are generally a few steps between the token probabilities after constraints and the token that gets chosen. Each of those steps that modify the probabilities of the tokens is called a sampler. The top-k sampler is one of the most common samplers. It only samples the top k most likely tokens. Here is what that could look like if we only keep the top 2 tokens (where k=2):

Generally, k is larger, but much smaller than the number of tokens in the model. The default in kalosm is 64.
Instead of parsing every token, we can skip parsing tokens once we find once we find the most probable k tokens. Since the LLM knows about the constraints, the valid tokens tend to have a very high probability so we can skip parsing the majority of the 128,000 tokens.
Conclusion
Structured generation gives you fine-grained control of generation while accelerating generation speed. More consistent outputs make it possible to use LLMs with typed APIs or guide LLMs along a longer multi-step process. I hope you found the visualizations useful and I would love to hear what use cases you have for structured generation.
If you need a complex structured generation parser, try Kalosm. You can write your parsers in Rust which means they run extremely fast. Feel free to join the discord to discuss this article.